
撰写日记
2024-1-18
2024年1月18日,随着除夕即将到来,各类软件平台上的年度报告依次出现在软件首推和朋友圈,突然想起来在好几年前就看见过一个GitHub的开源项目——WeChatMsg(事实上昨天晚上就又在B站刷到这个开源项目了),能够提取微信聊天,加上这几年的分析模型,我在想能不能做一个和小昕昕的聊天报告,在B站上搜集了很久,加上要学Python,于是从今天开始准备以Python作为处理语言对我和小昕昕的聊天消息进行分析~
2024-1-17
今天在B站看到一个视频
不过我发现这个开源项目完全没做完... ...还以为能够直接懒狗一步到位... ...
2024-1-25
很长时间没有更新了,还是在Github上直接搜索比较方便,找到了之前的那个开源项目WeChatMsg,利用留痕将小叶叶和小昕昕的聊天记录单独提取出来啦!然后就是摸索一下分析方法~
2024-1-26
将聊天记录的CVS文件丢到微词云获得了词云图!终于开发第一步()。真不知道得做到什么时候。
2024-2-1
一个大佬在博客撰写了WeChatMsgAnalysis方法与部分代码教程,照葫芦画瓢,希望就在眼前!
2024-2-2
遇到瓶颈,很晚了还是没有弄清楚某部分代码,Python还能这么难?
2024-2-3
鸽了
2024-2-4
好好睡了一觉起来灵感大爆发!感觉今天就能拿下!没忍住跟小昕昕说了我在写报告,结果小昕昕猜出来了!这这这,为什么!?我还说给个惊喜呜呜呜... ...小昕昕说在B站有推给她的视频,感觉可能是因为我俩最近在分享B站视频,然后我一直在搜索微信聊天分析,就推给她了呜呜呜,算了,含着眼泪做下去。
总体分析
从开始聊天到2024年2月4日的数据分析!
聊天类型
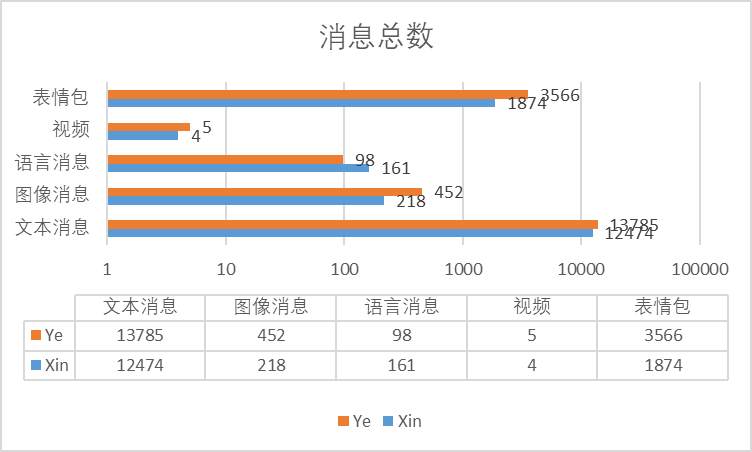
以消息每条作为计数1,根据文本,图片,语音以及视频和表情包对消息进行分类,统计得到以下表格:

根据以下数据,以小昕昕的各类消息数量为基准Ai(i=1,2,3 ...)计算,设小叶叶各类消息为Bi,得到各类消息的数量差值Ci,以Ci/Ai得到差值比,来看一看小叶叶和小昕昕的各类聊天消息多少!

什么意思呢?也就是说,小叶叶在文本消息类比小昕昕多了3579条,比小昕昕的多了12.5%其他消息以此类推!除了语音和视频,小叶叶发的条数远远多于小昕昕!
虽然小昕昕之前说自己不会喜欢不是特别熟悉的时候别人发语音,但是她自己还是比较喜欢发语音的~最早追溯到九月十六号我们的聊天,聊到关于她的辅修课~
消息长度
根据GitHub的WechatAnalysis开源项目,用Python代码对消息进行长度分析
mu, std = 0, 0
data = {"Length": [], "Person": []}
for i in range(2):
length = [len(textFilter(i)) for i in texts[i]]
data["Length"] += length
data["Person"] += [labels[i]] * len(length)
if np.mean(length) + sN * np.std(length) > mu + std:
mu, std = np.mean(length), np.std(length)
xlim = int(np.ceil(mu + sN * std))
data = pd.DataFrame(data)
bins = np.linspace(0, xlim, xlim + 1)
ax = sns.histplot(
data=data,
x="Length",
hue="Person",
bins=bins,
multiple=multiple,
edgecolor=".3",
linewidth=0.5,
palette="dark",
alpha=0.6,
)
ax.set_xlim(0, xlim)
ax.set_xlabel("Length of Message")
ax.figure.set_size_inches(8, 4)
ax.figure.set_dpi(150)
plt.show()
plt.close()获取到以下表格:

在短于5个字的消息小昕昕所发多于小叶叶,但是一旦超过5个字,小叶叶跟个话痨一样!小昕昕比较偏向于发比较短的语句,小叶叶喜欢写长文,特别是小作文(bushi)。
聊天时间!
以每日每个时段的聊天消息数量平均数作为计算目标,得到以下代码:
data = {"Time": [], "Person": []}
for i in range(2):
hour = dfs[i]["hour"].to_list()
data["Time"] += hour
data["Person"] += [labels[i]] * len(hour)
data = pd.DataFrame(data)
bins = np.arange(0, 25, 1)
ax = sns.histplot(
data=data,
x="Time",
hue="Person",
bins=bins,
multiple=multiple,
edgecolor=".3",
linewidth=0.5,
palette="dark",
alpha=0.6,
)
ax.set_xticks(bins)
ax.set_xticklabels(bins)
ax.set_xlabel("Hour")
ax.set_xlim(0, 24)
sns.move_legend(ax, loc="upper center", bbox_to_anchor=(0.5, 1.2), ncol=2)
ax.figure.set_size_inches(8, 4)
ax.figure.set_dpi(150)
plt.show()
plt.close()表格如图
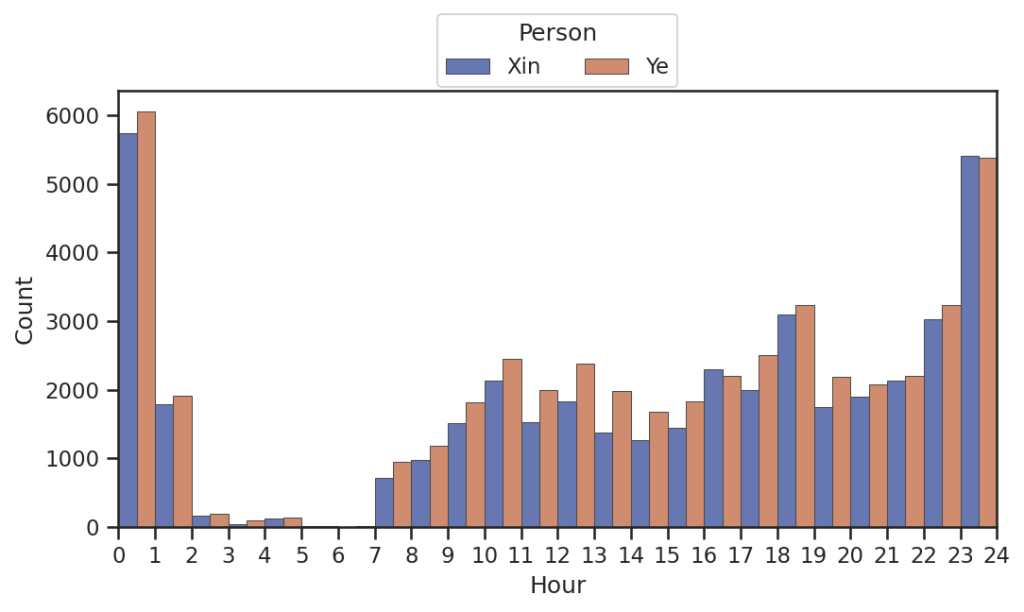
看来我俩聊天多的时间还是比较阴间的……居然最晚到四五点都还在聊天!总是聊天熬夜到两点,之后还是要早点睡的……比较都在一起了,线下多交流交流嘿嘿!
聊天时间分布图()
再将所有周一总数,所有周二总数,所有周三总数... ...作为计量,得到一周内聊天的消息多少!得到以下表格~
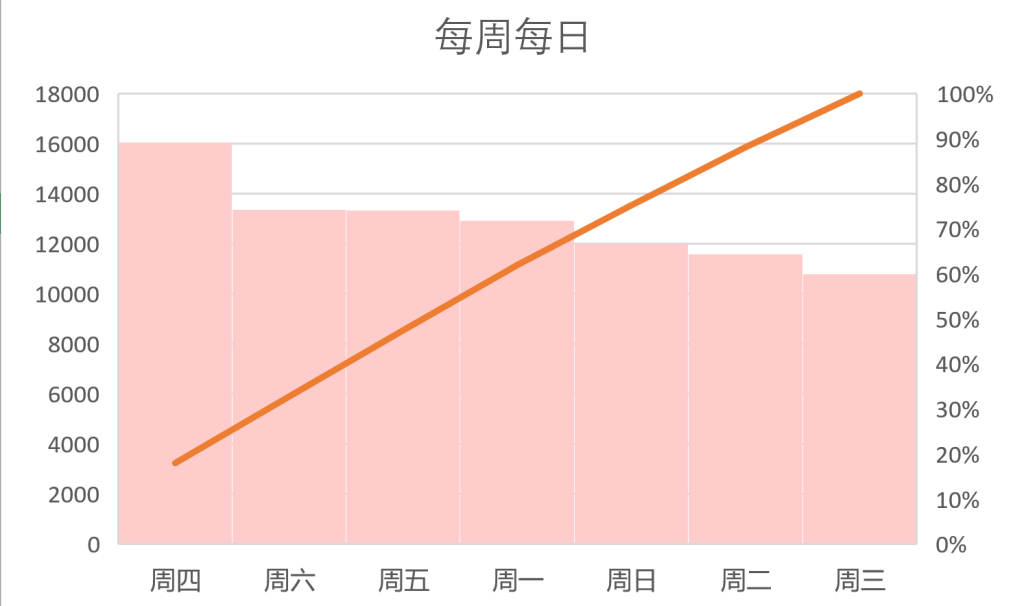
为什么周四最多周二周三最少呢?!
根据我的分析,大概是因为周二是通识课,小叶叶和小昕昕一直在一起,就不用发消息啦,而周三的英语课小昕昕认真听课就和小叶叶聊的少(应该是吧?),但是周四立马戒断,加上小叶叶上午有自己的英语课和小昕昕在一起机会少,就框框聊天()。
聊天热力图
以每周聊天消息总数作为聊天热力比较,根据以下代码得到以下表格,横坐标是每周起始日期!
grouper = pd.Grouper(key="StrTime", freq="W-MON")
data = df.groupby(grouper)["Count"].sum().to_frame()
data.index = pd.date_range(start=wStart, end=wEnd, freq="W-MON").strftime("%m-%d")
data.columns = ["Count"]
vM = np.ceil(data["Count"].max() / wTicks) * wTicks
norm = plt.Normalize(0, vM)
sm = plt.cm.ScalarMappable(cmap="Reds", norm=norm)
ax = sns.barplot(x=data.index, y=data["Count"], hue=data["Count"], hue_norm=norm, palette="Reds")
ax.set_xlabel("Date")
plt.xticks(rotation=60)
for bar in ax.containers:
ax.bar_label(bar, fontsize=10, fmt="%.0f")
ax.get_legend().remove()
axpos = ax.get_position()
caxpos = mtransforms.Bbox.from_extents(axpos.x1 + 0.02, axpos.y0, axpos.x1 + 0.03, axpos.y1)
cax = ax.figure.add_axes(caxpos)
locator = mticker.MultipleLocator(wTicks)
formatter = mticker.StrMethodFormatter("{x:.0f}")
cax.figure.colorbar(sm, cax=cax, ticks=locator, format=formatter)
ax.figure.set_size_inches(20, 8)
ax.figure.set_dpi(150)
plt.show()
plt.close()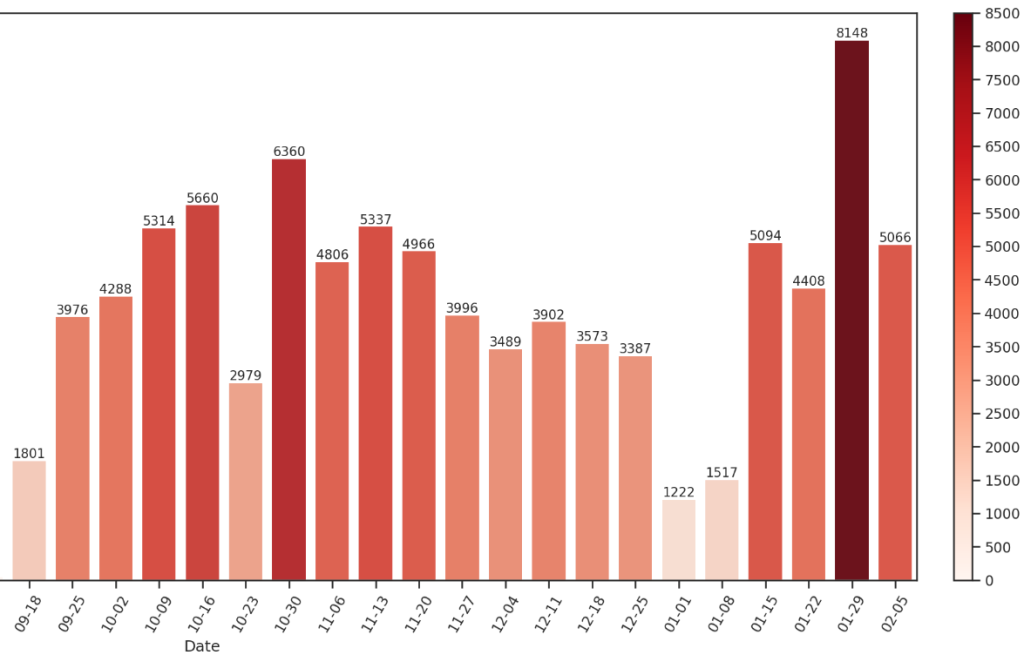
从逐渐熟悉的时候聊天热度上升,然后找机会线下在一起的时候热度减少,一直到十一月在一起,聊天数量又逐渐递增~然后渐渐地因为线下时间增加,尤其是期末考试接近了,线上聊天热度减少。放假后又猛增!一天到晚聊个不停,特别是最近()。
词分析
以下词分析利用PaddleNLP语音文本分析模型,这个模型常用于文本聊天等词汇分析,这个折腾挺久... ...不过!终于攻克掉啦!
常用词热度贡献
根据消息,依据中文停用词排除词汇,再根据出现频率来排列频繁使用消息词,并且从上到下排名,然后以各自发送次数/总出现次数作为热度贡献,得到以下表格(小叶叶好伤心呀,小昕昕就会噢呜呜呜,哭唧唧,不过还是小叶叶比小昕昕更较热情)。
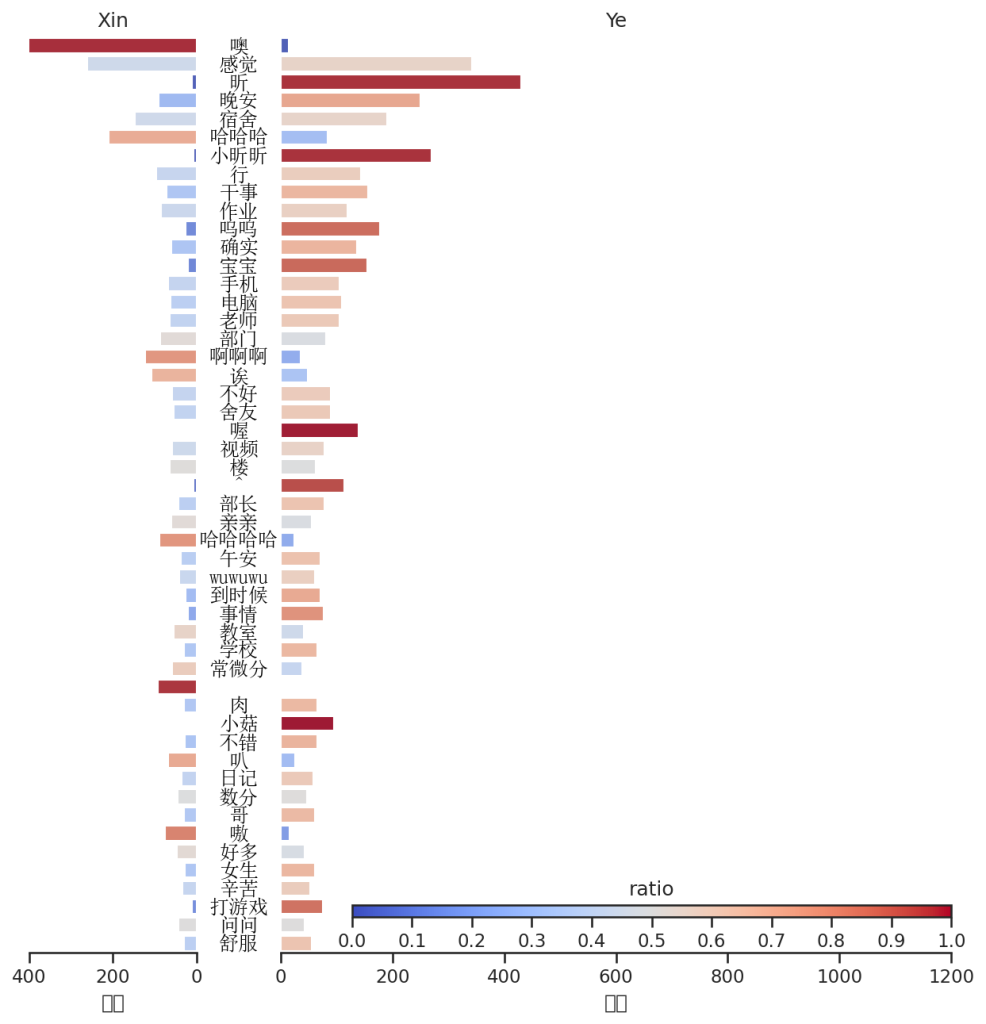
情感分析模型
获取感情分析模型~
话说这俩模型还真大!我的服务器还没下过这么大的文件... ...但是由于模型是采取的国外的一个语言文本模型,可能不太适用于我们Chinese?
该模型的分数范围为[-1,1]
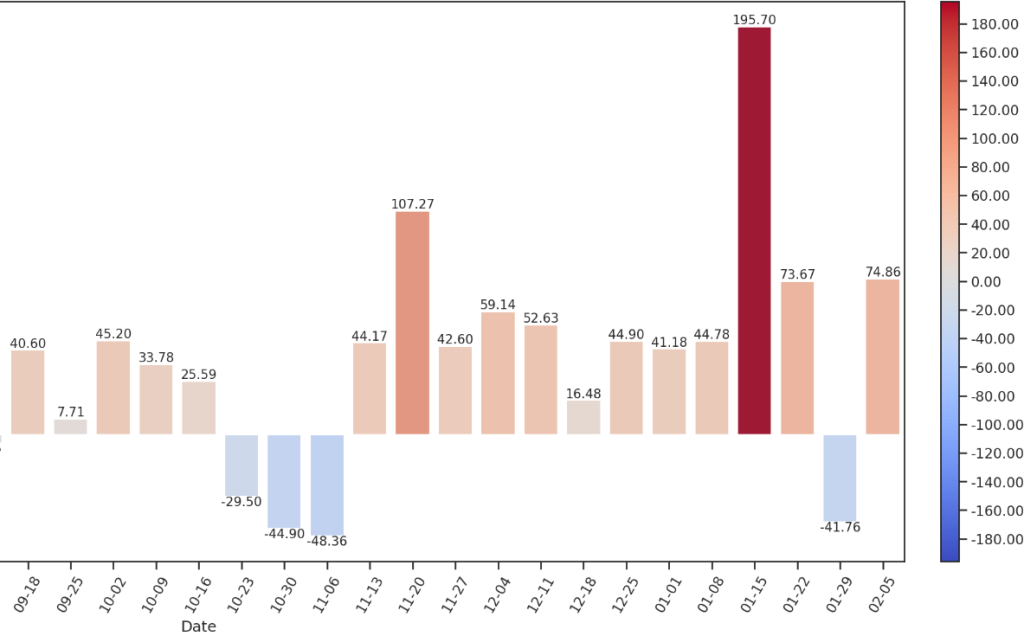
每周累计情感
将每周的情感积分积累,算的每周的情感得分~在11月在一起前三周情感得分并不高,实际上这段时间由于小叶叶总在找借口和小昕昕呆在一起,他俩聊天的频率在这段时间并不高,所以分数暴跌,不过在一起后短时期内情感指数又暴增了一会!随后的期末临近,小叶叶和小昕昕一起在图书馆复习,聊天消息量减少,就没有那么高了呜呜呜。放假后明显有一段时间的阶段,情感指数暴增!
总体情感得分
从-1分到1分查看小叶叶和小昕昕的分数分布,其中深蓝色为重叠部分,淡蓝色为小昕昕,黄棕色为小叶叶情感得分。其中突出部分为模型中解释的普通聊天模式,是正常部分
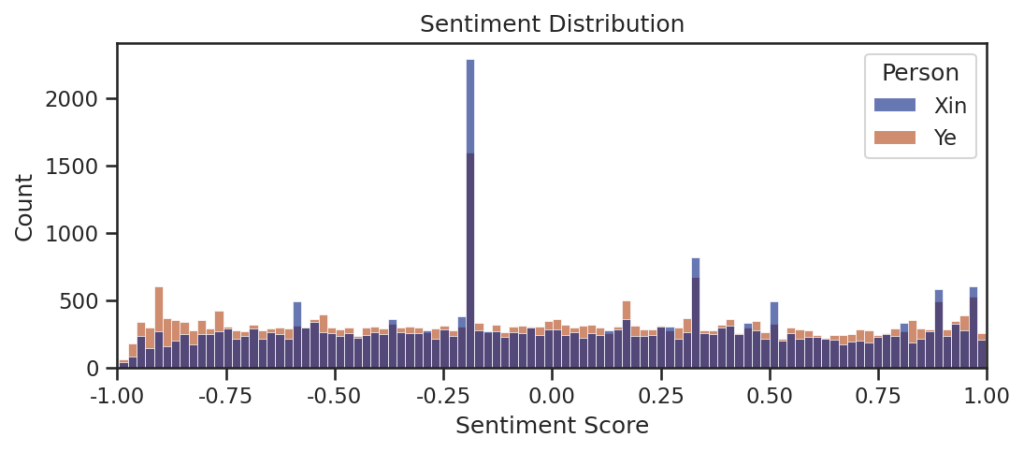
大部情感指数里小叶叶的情感表现大于小昕昕的情感表现,一些较为重合的情感指数里还是小昕昕得分更为频繁()。
词云
用的我们比较喜欢用的表情包做词云,结果!感觉有些看不出来原图了()



结果:
小昕昕


小叶叶


小叶叶和小昕昕


小叶叶和小昕昕在一起前的聊天分析
消息类型分类总数分析
差值和差比表如下:

小昕昕在图片方面的消息远远少于小叶叶,但是语音消息很多
消息长度区间分布
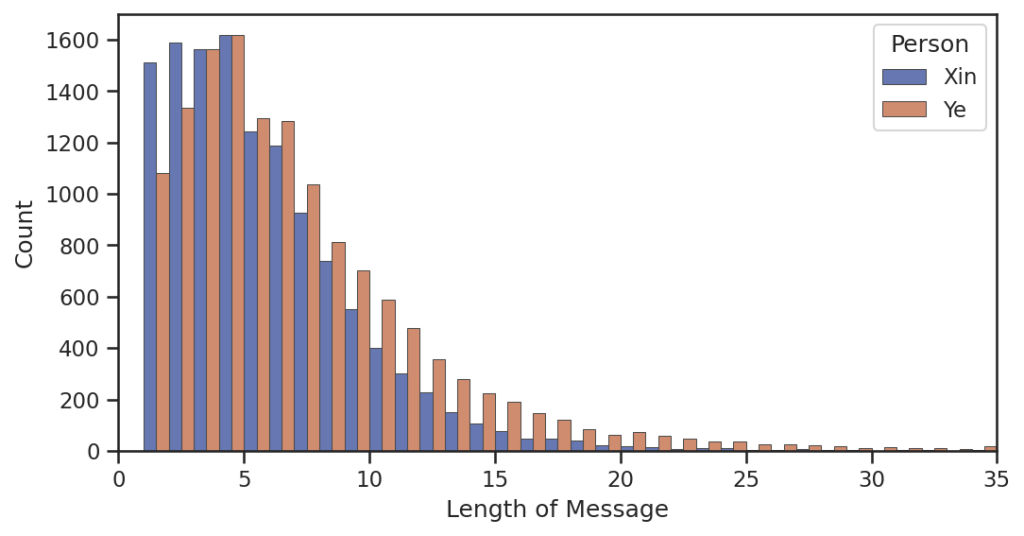
看来在一起前小叶叶还是比较喜欢发长段文字消息,小昕昕还是比较懒()。
聊天时间分布
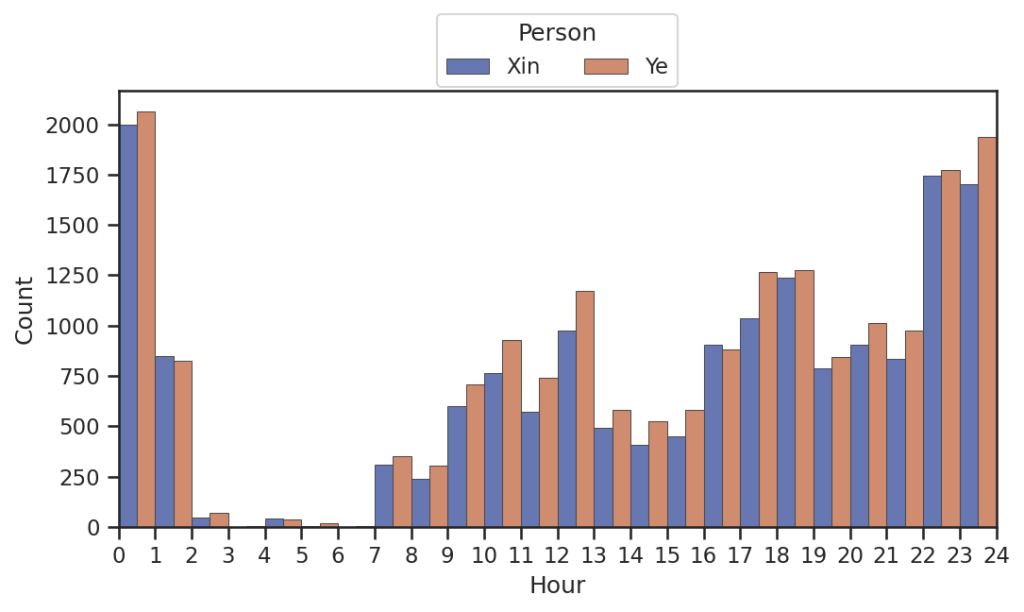
在一起前就很喜欢夜聊()。
聊天热力周
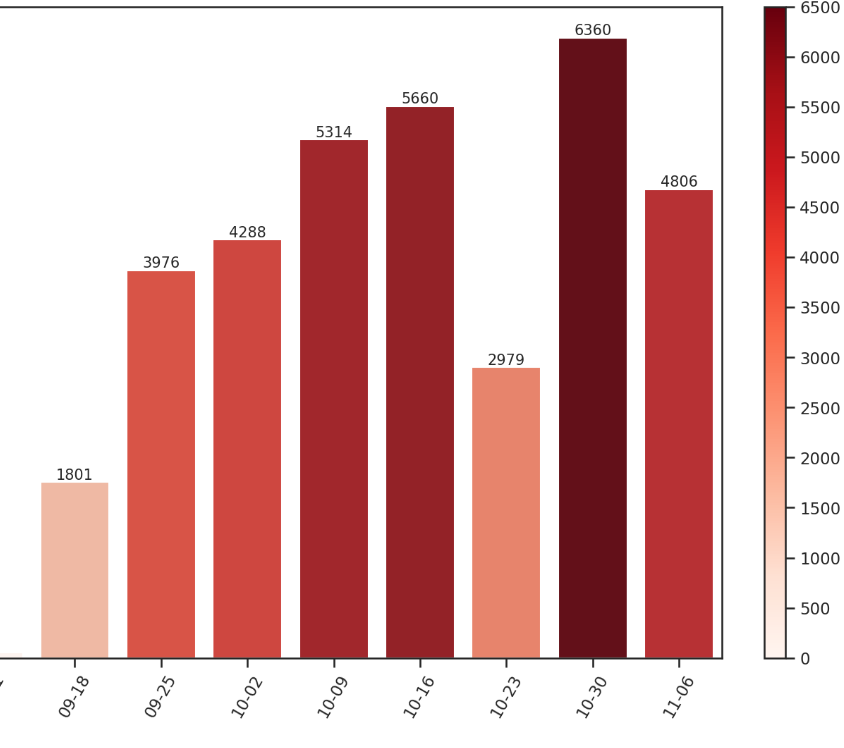
在开学后小叶叶和小昕昕聊天热力不断上升,但是在十月二十三这周热度下降!这是为什么呢?!!!
翻看了以下,原来是在十月二十二日当天小叶叶让小昕昕极度生气了,然后一天没有怎么聊天,导致十月二十三日也是直到晚上才有聊天... ...
词云


用词排名以及贡献值
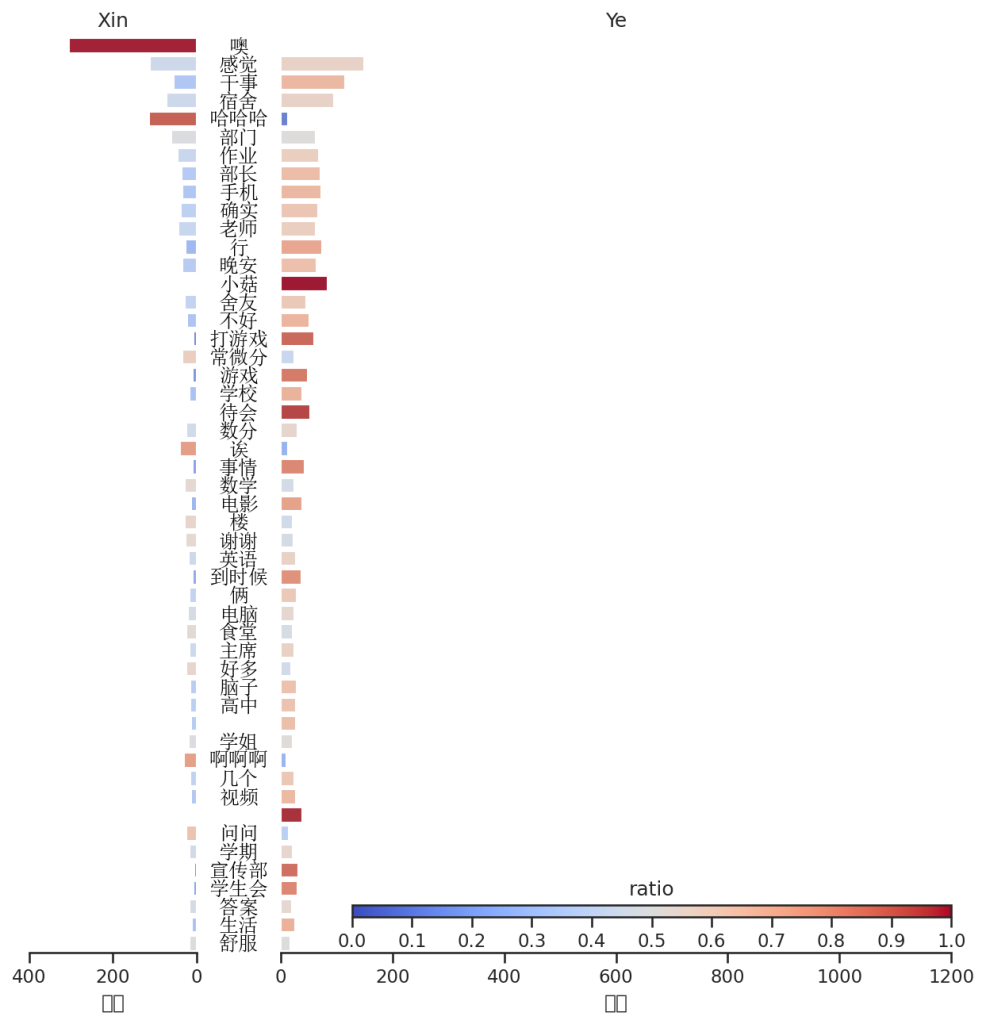
这段时间由于在熟悉了解阶段,聊天都比较偏向于生活学习之类的喔,但是小昕昕是真的喜欢噢这个词!
小叶叶和小昕昕在一起后的聊天分析
消息类型分类总数分析
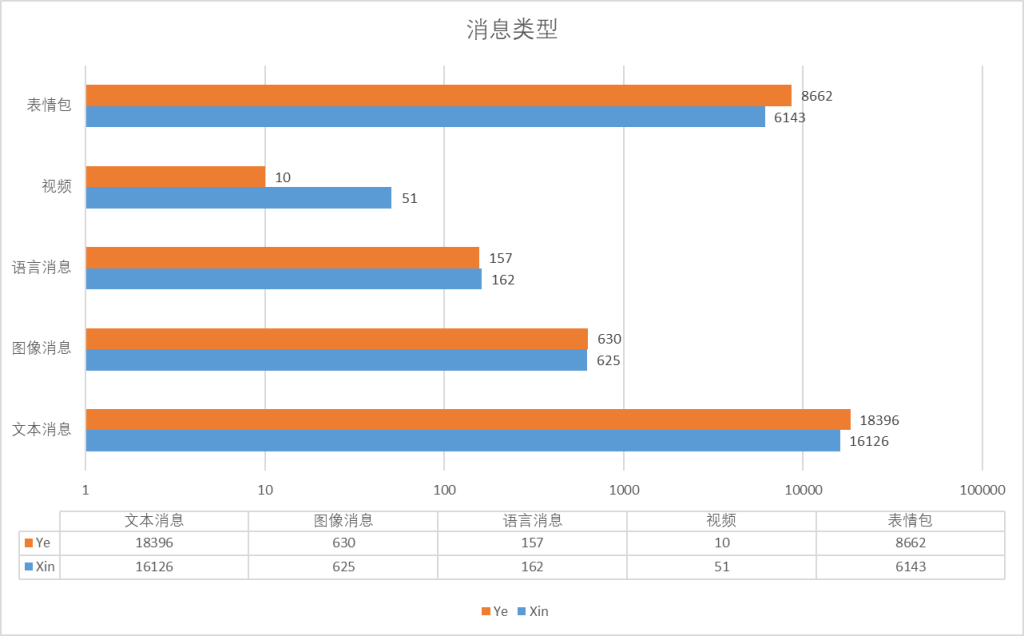
同样的,以小昕昕的消息量为基础得到差值和差比

文本消息小昕昕还是远远发的少于小叶叶!哼哼!和在一起前相比,文本类消息虽然数量增加了但是比小叶叶发的更少了()。
消息长度区间分布
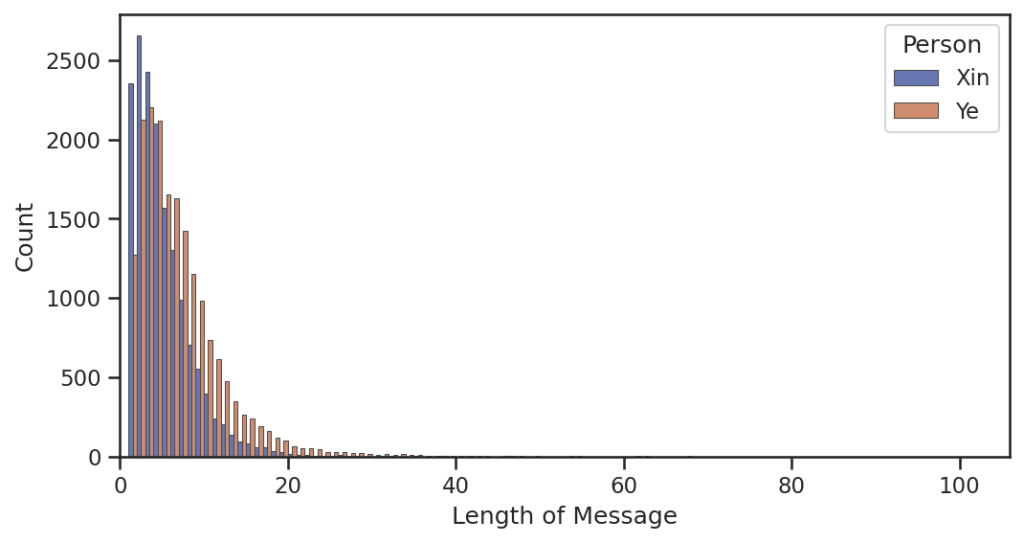
之前是五个字以下小昕昕发的比小叶叶多,这回是三个字了!看小叶叶多么热情!
聊天时间分布图
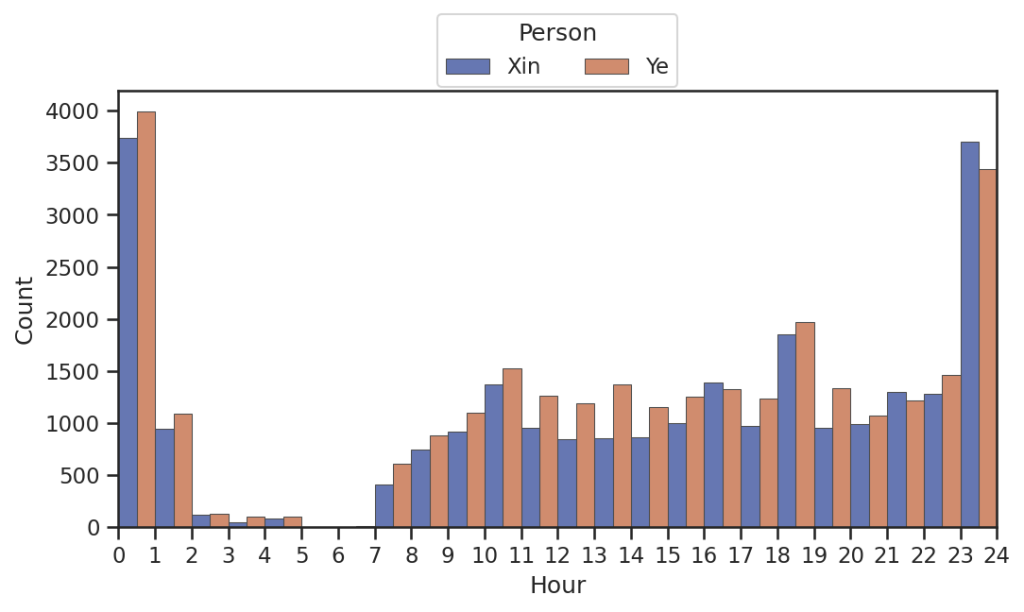
在一起后聊天时间还是阴间(),特别是两三四五点的条数增加了()。
周X聊天总数
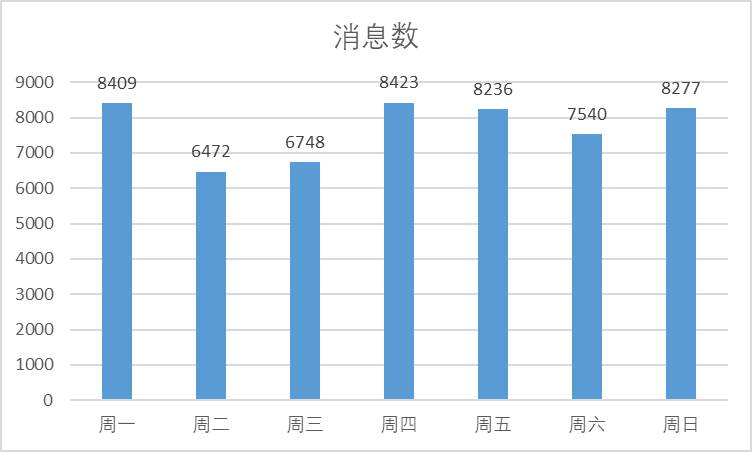
周二周三因为课程在一起的时间多,聊天数量少,加上在一起后一段时间小昕昕辅修课快结课了,小叶叶和小昕昕在初期线上聊天比之前少了,不过后来又结课了,在图书馆一起学习噜~
聊天热力周
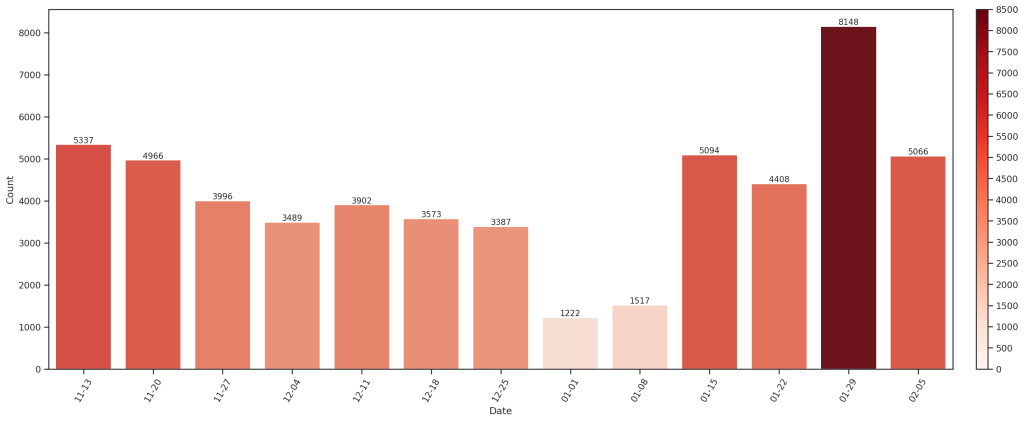
在一起的开始时间段因为线下的时间更多聊天热度下降,尤其是期末周那段时间,各回各家后就又热聊起来,特别是最近()。
词云



用词排名以及贡献值
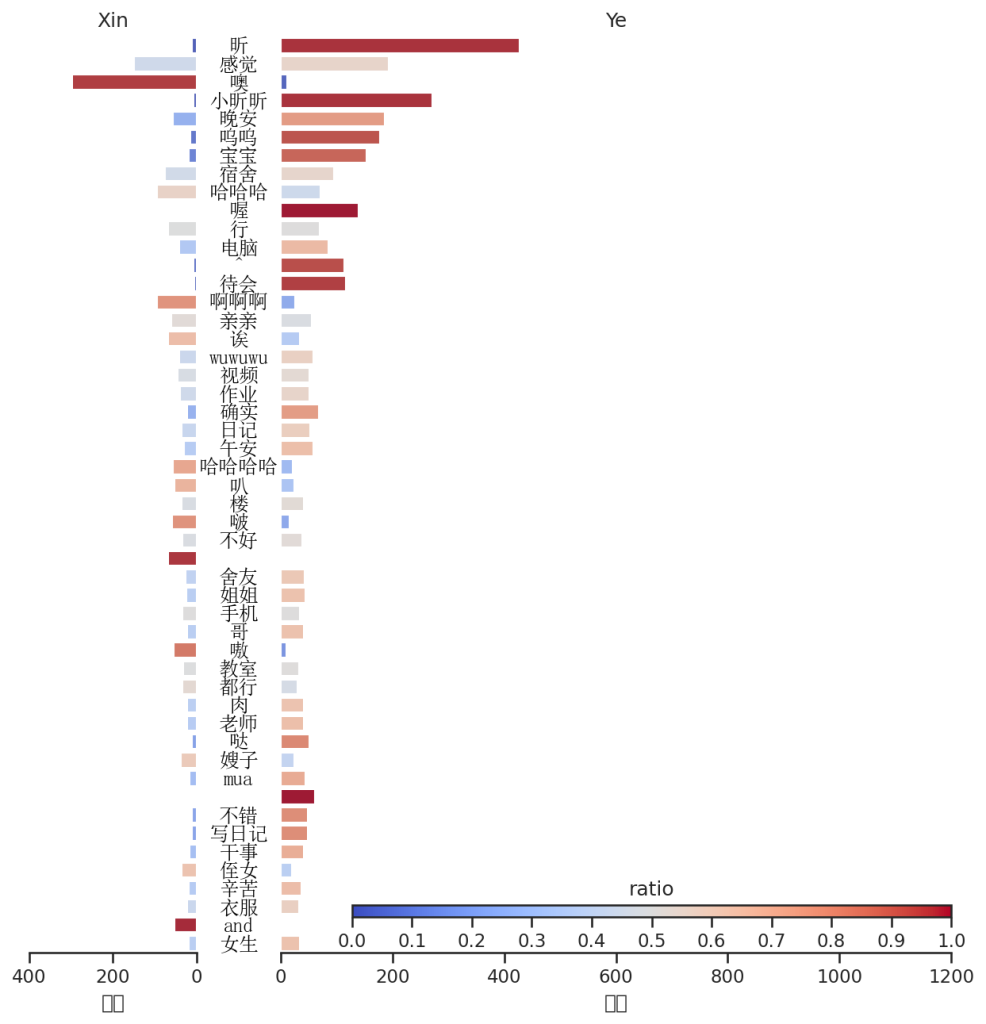
上半假期聊天分析
在学校大多时候和小昕昕在一起没有办法完全体现与小昕昕的聊天分析,于是采取2024/1/11-2024/2/4这段时间的聊天作为分析!
各类消息总数
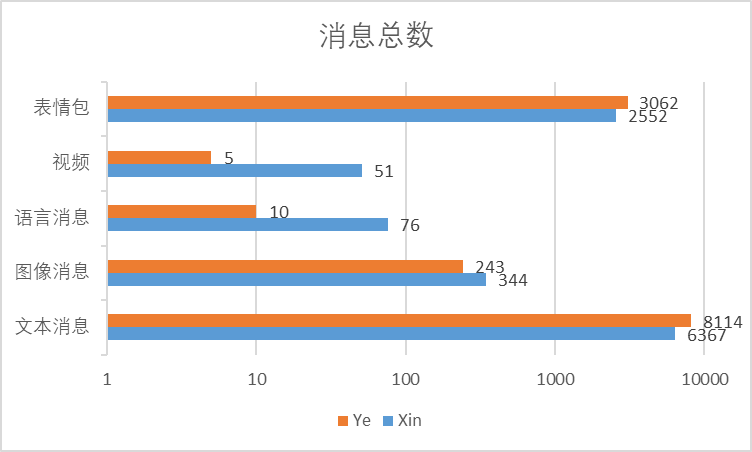
差值差比图

文本消息还是小叶叶多!但是图像和语音消息还有视频小昕昕发的更多惹wuwuwu。
消息长度分布
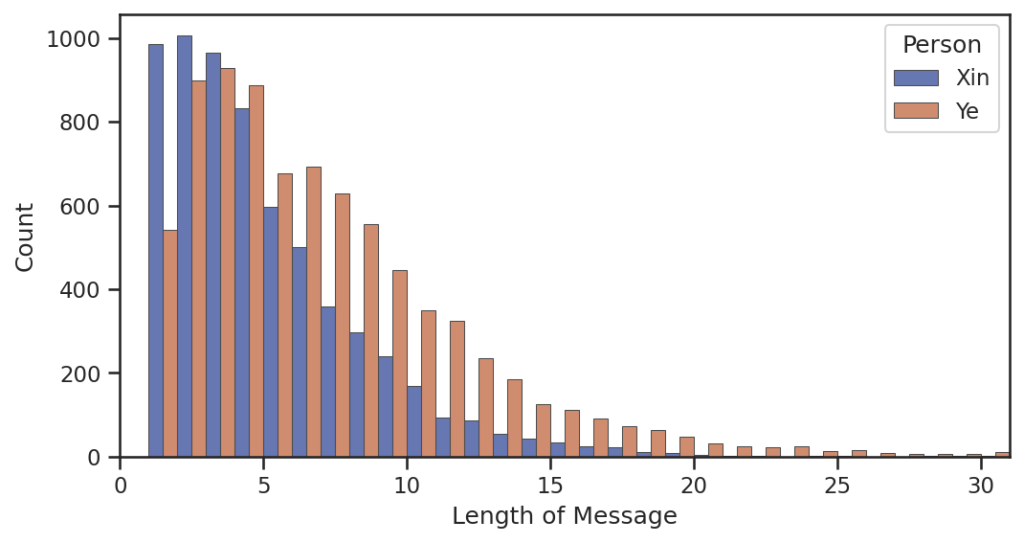
小叶叶就知道,小昕昕在长消息肯定不如小叶叶!
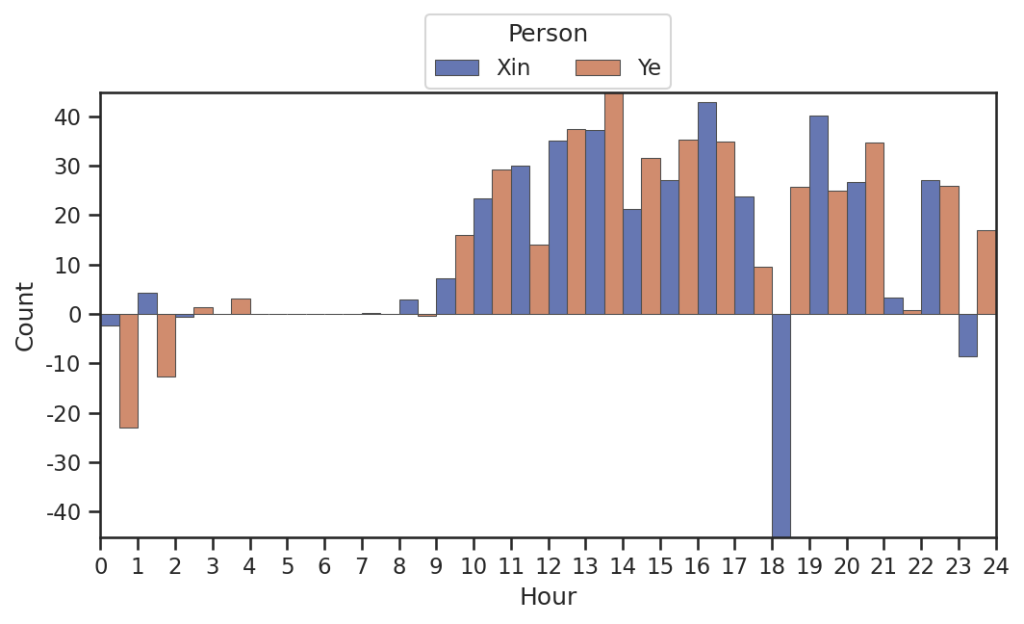
每日聊天时间段
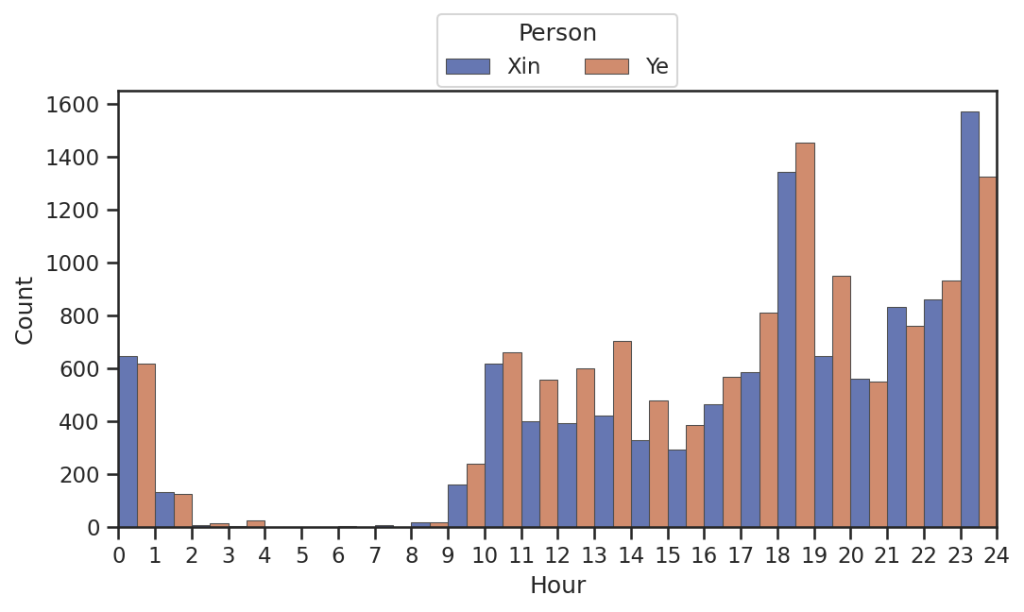
如图,在接近吃饭的时候聊天多,比如午饭(10点)和晚饭(18点)(别问为什么没有早饭)尤其是晚上的时候小叶叶和小昕昕聊的非常多!大部分情况下小叶叶发消息比小昕昕更频繁,但是大半夜的小昕昕发的更多?!
聊天热度图!

一月二十八号这条聊啥了怎么这么火热?!原来是小昕昕和小叶叶视频,但是小昕昕不能开语音呜呜呜!然后小昕昕只能打字惹!至于中间空白部分,翻找记录,原来是小昕昕在外面玩顾不着小叶叶呜呜呜!
词云


用词排行以及贡献值
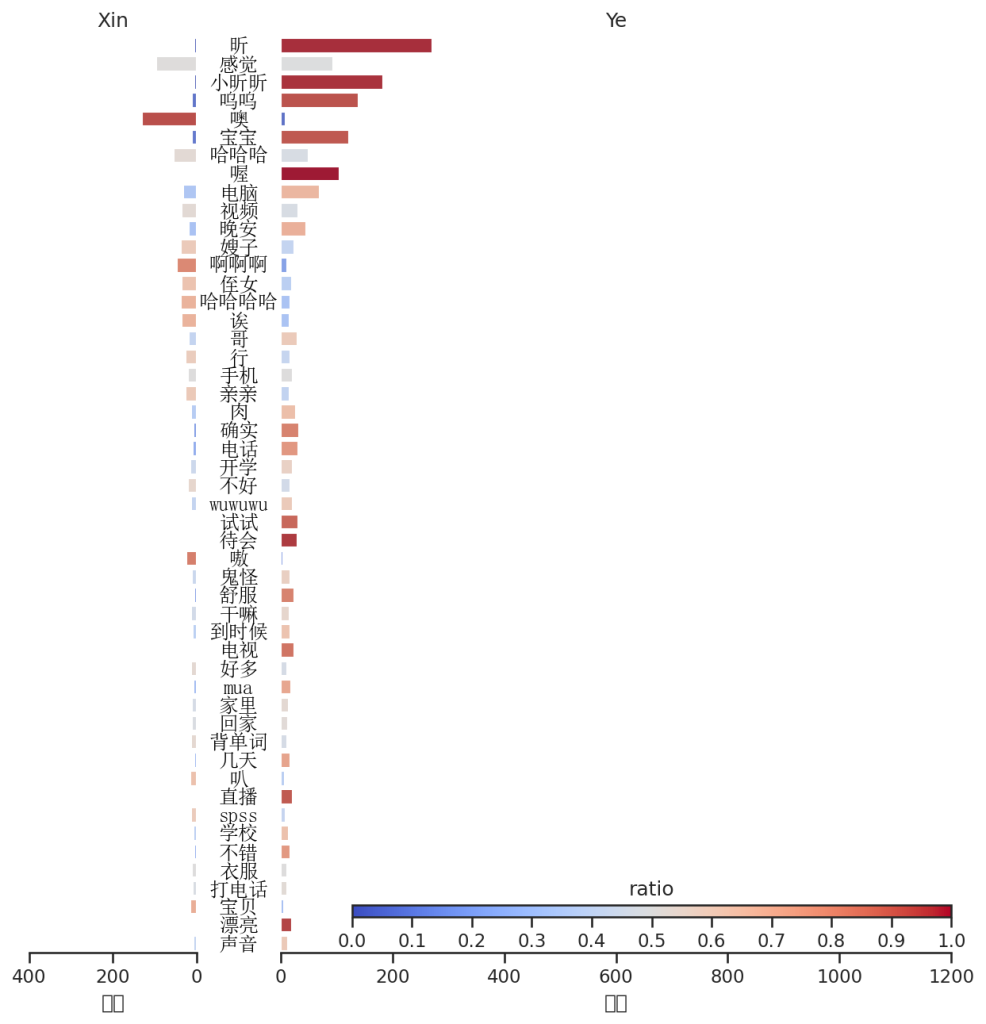
哼哼,小叶叶对小昕昕的喜欢贯穿始终!
情感指数
平均代表某时段内稳定的情感尺度,越高代表积极情绪表达值越高,积累代表代表某时段内总共的情感分数,越高代表积极情绪表达次数更多
从以下表图可以发现小昕昕在积极情绪表达值偏向更高,小叶叶积极情绪表达更频繁
每日每时段情感平均指数
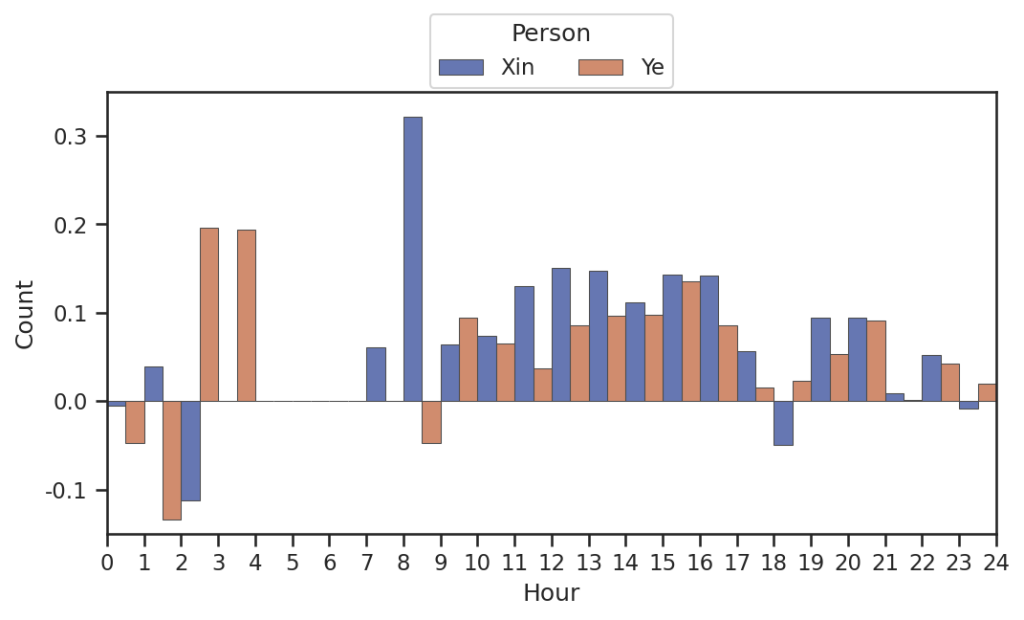
每日每时段情感积累指数
Comments NOTHING